SSAFIT NEWS
실시간 뉴스 데이터를 수집하고, 텍스트 임베딩 기반으로 유사 뉴스 추천 및 인사이트 분석이 가능한 플랫폼을 구축합니다.
Features
실시간 뉴스 수집
RSS 피드를 통한 실시간 뉴스 데이터 수집, 한국경제, AI타임스, 전자신문 등 주요 IT 언론사 데이터 수집, 수집된 데이터는 Kafka 토픽으로 전송
스트리밍 처리
Kafka → Flink 기반 실시간 데이터 처리, 뉴스 본문 전처리 및 정제, 중복 뉴스 필터링 및 데이터 정합성 검증, OpenAI GPT-4를 활용한 카테고리 분류 및 키워드 추출
데이터 분석 및 저장
뉴스 키워드 추출 및 카테고리 분류, OpenAI Embedding API를 활용한 텍스트 벡터화, PostgreSQL(pgvector) 및 Elasticsearch 이중 저장, HDFS 기반 실시간 데이터 아카이빙, 실시간 검색 및 추천 기능 지원
리포트 생성
Spark 기반 일간 뉴스 분석, 키워드 트렌드 및 시각화, 카테고리별 기사 분포 분석, PDF 형식의 분석 리포트 자동 생성, HDFS 기반 리포트 아카이빙
Tech Stack
Data Collection & Processing
Storage
Embedding & NLP
Orchestration & Infrastructure
Monitoring & Visualization
Core Technologies
실시간 데이터 파이프라인
Kafka → Flink 기반 실시간 데이터 처리, 뉴스 본문 전처리 및 정제, 중복 뉴스 필터링 및 데이터 정합성 검증, OpenAI GPT-4를 활용한 카테고리 분류 및 키워드 추출
텍스트 분석 및 임베딩
OpenAI GPT-4 기반 키워드 추출 및 카테고리 분류, 뉴스 본문에서 핵심 키워드 5개 추출, 15개 IT 기술 카테고리 분류, OpenAI Embedding API를 활용한 1536차원 벡터 생성
데이터 저장 및 검색
PostgreSQL(pgvector) 및 Elasticsearch 이중 저장 구조, 벡터 기반 유사 뉴스 검색, 실시간 검색 및 추천 기능, HDFS 기반 데이터 아카이빙
일간 리포트 생성
Spark 기반 일간 뉴스 분석, 키워드 트렌드 및 시각화, 카테고리별 기사 수 분포 분석, matplotlib을 활용한 PDF 리포트 자동 생성
My Role
데이터 파이프라인 설계
전체 시스템 아키텍처 설계, 데이터 흐름 및 저장소 설계, 확장성 고려한 시스템 구성
실시간 처리 구현
Flink 기반 스트리밍 처리 로직, 데이터 전처리 및 정제 파이프라인, 실시간 모니터링 시스템 구축
데이터 분석 및 저장
Spark 분석 로직 구현, Elasticsearch 색인 설계, 벡터 검색 최적화
시스템 운영
Airflow DAG 설계 및 구현, Docker 기반 컨테이너화, 모니터링 및 로깅 시스템 구축
Results
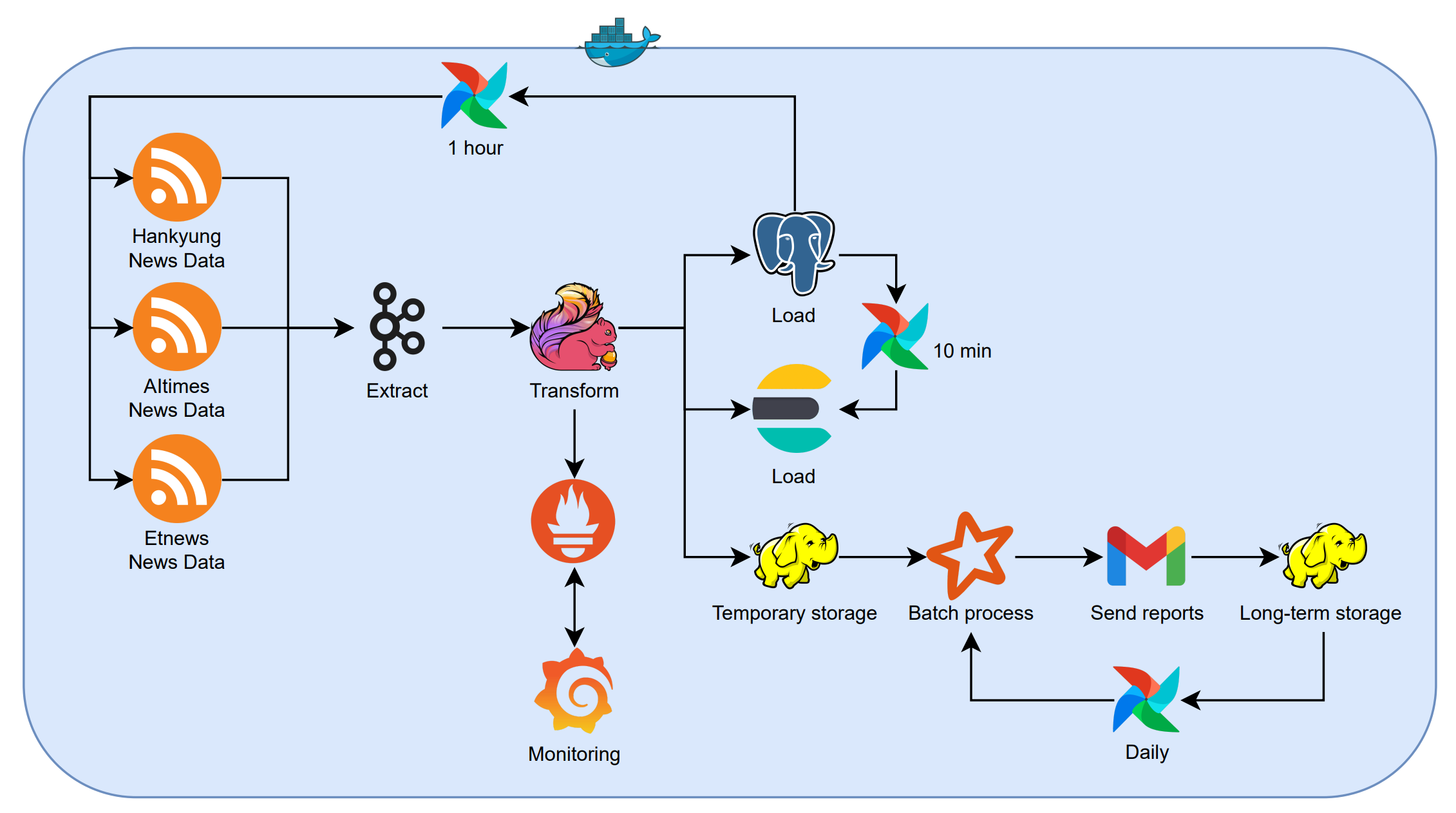
데이터 파이프라인
데이터 파이프라인 구조 및 각 단계 설명
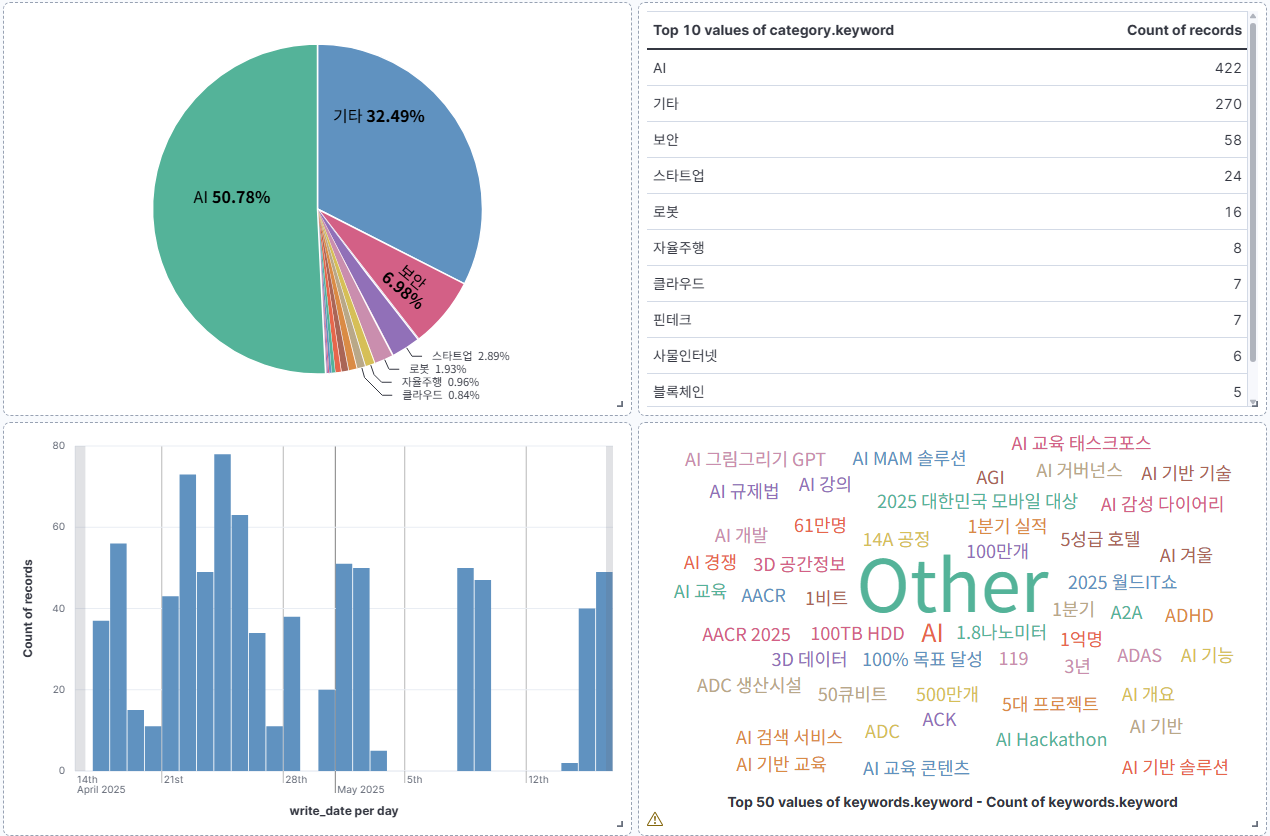
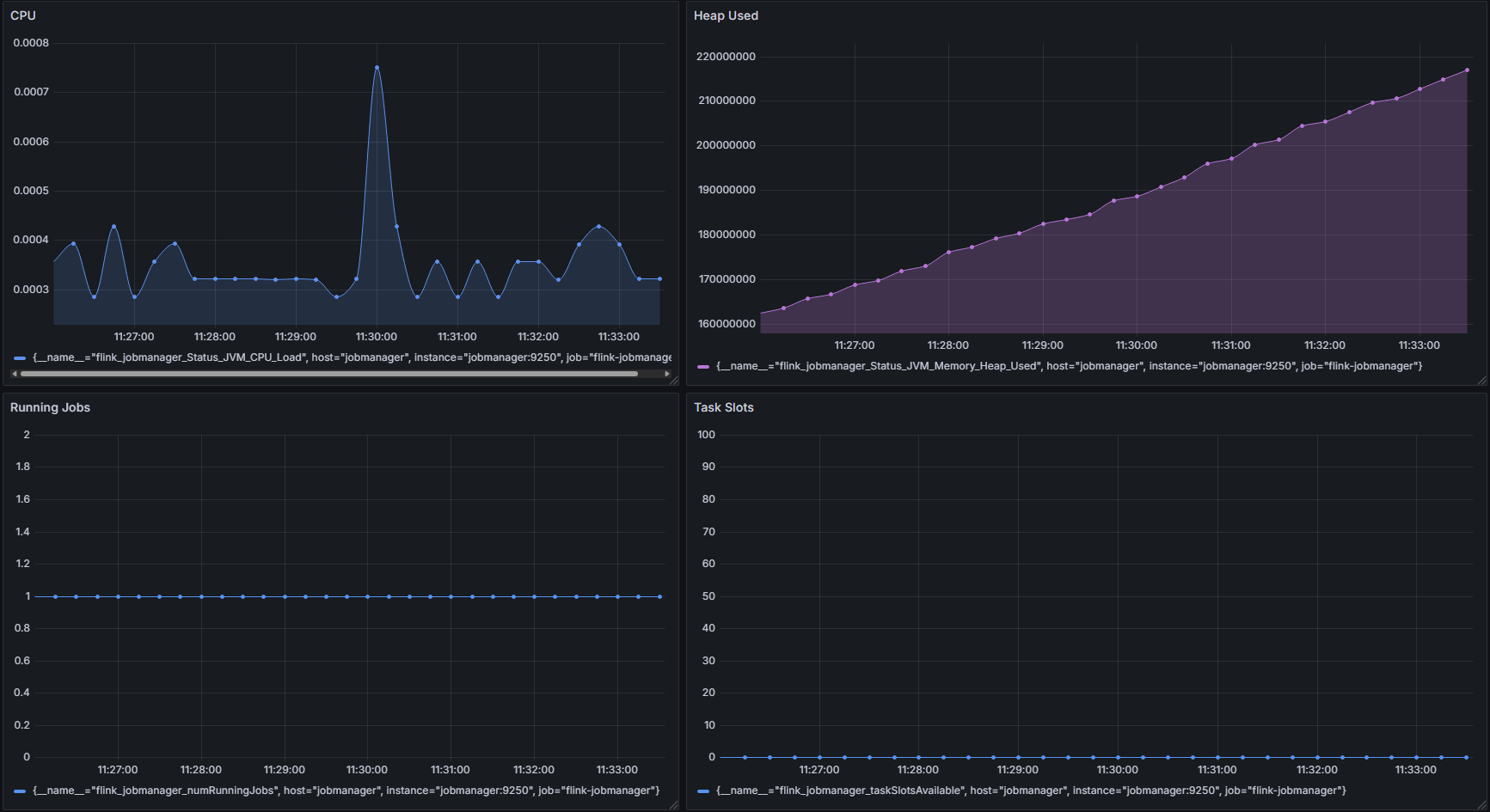
워크플로우 모니터링
DAG 실행 상태 및 로그 모니터링, DAG 실행 이력 및 성공/실패 현황, 태스크별 실행 시간 및 리소스 사용량, 실시간 로그 확인 및 디버깅
Project Structure
프로젝트 구조
모듈화된 구조로 각 컴포넌트의 독립적인 개발과 테스트가 가능
. ├── batch/ # 배치 처리 관련 코드 │ ├── dags/ # Airflow DAG 정의 │ │ ├── daily_report_dag.py │ │ ├── sync_postgres_to_es.py │ │ └── streaming_dag.py # 실시간 뉴스 수집 DAG │ ├── scripts/ # 실행 스크립트 │ │ ├── spark_daily_report.py │ │ ├── consumer.py │ │ ├── db_config.py │ │ ├── db_utils.py │ │ ├── models.py │ │ ├── news_model.py │ │ ├── preprocess.py │ │ ├── producer_aitimes.py │ │ ├── producer_hankyung.py │ │ ├── producer_etnews.py │ │ └── config/ │ ├── data/ # 데이터 저장소 │ │ └── daily_reports/ │ ├── logs/ # 로그 파일 │ └── output/ # 출력 결과물 ├── docker/ # Docker 관련 파일 │ ├── Dockerfile.airflow │ ├── Dockerfile.spark │ ├── Dockerfile.flink │ ├── requirements.txt # Python 패키지 의존성 │ ├── flink-conf.yaml # Flink 설정 파일 │ └── flink-entrypoint.sh # Flink 실행 스크립트 ├── hadoop/ # Hadoop 관련 설정 및 파일 ├── img/ # 이미지 파일 저장소 ├── setup/ # 초기 설정 스크립트 ├── test.py # 테스트 스크립트 ├── .env # 환경 변수 설정 ├── .gitignore # Git 무시 파일 목록 ├── docker-compose.yaml # Docker Compose 설정 └── requirements.txt # Python 패키지 의존성
Installation
Requirements
- Docker
- Python 3.8+
- Java 11+
- OpenAI API Key
- PostgreSQL
- Elasticsearch
- Apache Kafka
- Apache Flink
- Apache Spark
- Apache Airflow
Steps
git clone https://github.com/choihjin/news-data-project.git cd news-data-project vi .env # 환경 변수 설정 docker-compose up -d --build docker-compose logs -f
Notes
- 환경 변수 설정이 필요합니다
- Docker와 Docker Compose가 필요합니다
- OpenAI API 키가 필요합니다
Awards
- 2025.05.29 1학기 프로젝트 우수상 수상 (삼성전자)